
我们真的需要为数据构建 AI Agent 吗?
数据工作所需的软件早已存在且非常成熟。唯一的问题一直是用户体验。AI 编程 Agent 解决了这个问题——根本不需要专门的数据 Agent。
一种新的产品品类正在涌现:AI 数据 Agent。这些专门构建的系统承诺能够导入你的数据、分析数据,并呈现结果——一切通过智能化、专门设计的 Agent 体验来完成。
我们认为这是在解决错误的问题。
软件早已存在
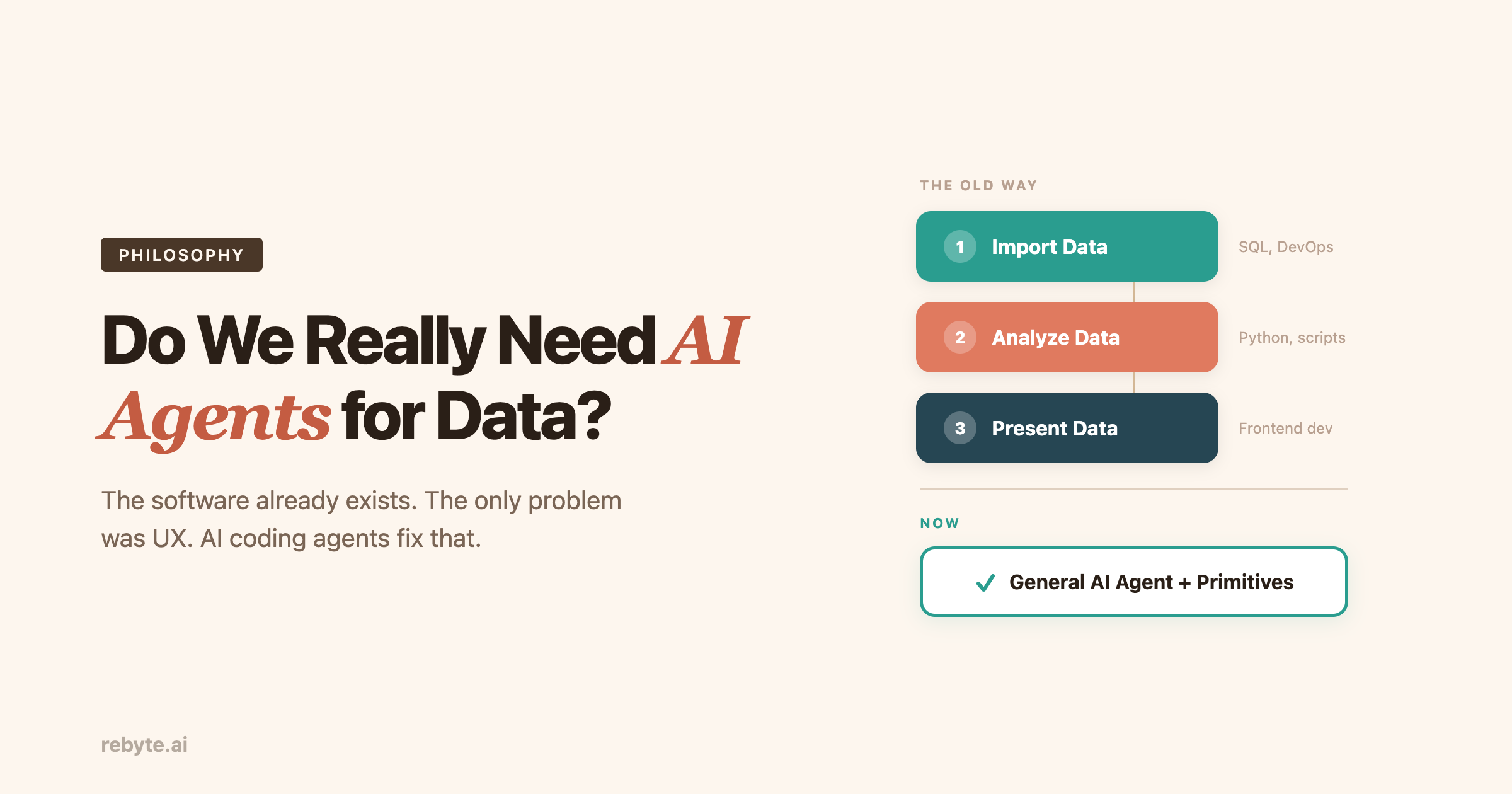
数据工作几十年来一直遵循相同的三步流程:
- 导入数据
- 分析数据
- 呈现数据
而每一步所需的软件不仅已经构建好了——而且非常出色。
导入。dbt、Airbyte、Fivetran、Singer、Apache Spark、自定义 ETL 脚本——数据摄取生态系统规模巨大。你可以从 CSV、API、数据湖、数据仓库或流式数据源中提取数据。几乎地球上每一个数据源都有相应的连接器。
分析。DuckDB 可以在单台机器上零配置查询数十亿行数据。pandas 和 polars 处理内存中的数据转换。SQL 是通用的。Jupyter notebook 将代码、输出和叙述整合在一处。R 语言内置了数十年积累的统计方法。这些工具不是玩具——它们支撑着全球最大公司的生产级分析。
呈现。D3.js 能生成有史以来最精美的数据可视化作品。Plotly 和 Vega-Lite 只需几行代码就能生成交互式图表。Observable、Streamlit 和 Gradio 可以将脚本转化为可分享的仪表盘。Matplotlib 和 seaborn 虽然不够美观,但拥有无限的灵活性。图表和可视化生态系统庞大、成熟,能够产出真正令人惊叹的输出。
这些工具已经经过 20 多年的打磨。基础工具从来不缺。它们一直都在。
人们之所以认为我们需要专门的数据 Agent,唯一的原因是现有软件对大多数用户来说太不友好了。
真正的问题一直是用户体验
工具本身没问题。问题在于使用这些工具的每一步都需要深厚的技术知识。
- 导入数据——配置 dbt 模型、编写摄取脚本、设置数据库 schema、管理认证凭据、处理数据类型转换。需要 SQL、DevOps 知识,通常还需要一名数据工程师。
- 分析数据——编写 Python 脚本、构建 SQL 查询、建立转换流水线、验证统计假设、处理边界情况。需要编程技能和领域知识。
- 呈现结果——选择合适的图表类型、配置 D3 或 Plotly、设计仪表盘样式、处理响应式布局、部署到可访问的地方。通常需要一名前端开发者。
三个步骤。三种不同的技能集。大多数人连其中一步都无法独立完成。
这就是为什么公司需要雇佣数据团队——不是因为软件不存在,而是因为其他人无法使用它们。用户体验的壁垒就是全部问题所在。
AI Agent 解决了用户体验层
这就是变革。一个通用的编程 Agent——配备一台云端计算机和标准工具——可以代表用户操作所有这些软件。它懂 SQL。它懂 Python。它懂 dbt、DuckDB、pandas、D3、Plotly,以及上百种其他工具。它已经掌握了工程师花费数年才学会的那些软件。
用户只需用自然语言说出自己想要什么。Agent 完成剩下的一切。
不需要专门的"数据大脑"。不需要定制的查询规划器。不需要专有的分析引擎。只需一个能力强大的编程 Agent 和工程师们使用多年的那些基础工具。
一个真实案例:Superstore 数据集
来看一个具体场景。你有一个 Superstore 数据集——大约 10,000 条零售交易记录,包含销售额、利润、品类、区域、物流和折扣等字段。一个典型的数据分析工作流是这样的:
- 理解并提出问题。你到底想知道什么?哪些品类最赚钱?折扣对利润率是有帮助还是有损害?家具品类是否表现不佳?提出正确的问题是最难的部分——也是大多数分析项目停滞的地方。
- 分析以验证假设。针对每个问题,编写 SQL 查询或 Python 脚本。运行它们,检查输出,排查边界情况,用不同的参数重新运行。这个过程是迭代的、繁琐的,需要技术能力和领域直觉。
- 呈现结果。将原始查询输出转化为人类可以阅读的内容——表格、图表、带有明确结论的报告。这就是大多数人彻底放弃的环节。
现在来看看当 AI 编程 Agent 处理每一步时会发生什么。
1. 提出问题
人类可能会想出三个待验证的假设。而 Agent 能生成数十个。它读取 schema、采样数据,并生成一份全面的假设清单——涵盖按品类的盈利能力、折扣影响、区域模式、物流效率和客户分群等维度。它可以自由探索,唯一的限制是时间而非想象力。它不会疲倦,也不会词穷。
2. 运行分析
针对每个假设,Agent 编写 SQL 查询并在 DuckDB 上运行,检查结果,然后迭代。如果某个查询揭示了意想不到的发现,它会深入挖掘——添加细分维度、计算相关性、运行后续查询。它不需要许可就能探索。它像资深分析师一样处理数据,只不过它能在人类完成三个假设的时间里完成一百个。
3. 呈现结果
这是 Agent 经常让人惊喜的地方。给定原始分析结果,它会生成一份精心排版的 HTML 报告——包含结论标签、格式化的数据表格、语法高亮的 SQL 查询,以及每项发现的清晰叙述。它还主动添加了一个额外的物流分析。输出不是原始的 CSV 数据导出。这是一份你可以直接发给相关方的文档。
只需一条提示词。无需安装特殊的数据技能。无需配置工作流。Agent 拥有一台装有 DuckDB 的云端计算机——和任何数据工程师使用的工具完全一样——它在极短的时间内比大多数人做得更好。
为什么通用 Agent 胜过专用 Agent
专用数据 Agent 针对一种狭隘的分析方式进行了优化。这听起来很有吸引力,但它制造了天花板。一旦任务超出 Agent 内置工作流的范围,你就卡住了。
通用编程 Agent 没有天花板。它可以:
- 编写 SQL、Python、R 或 JavaScript——任务需要什么就用什么
- 在分析过程中从 DuckDB 切换到 pandas 再到 Jupyter notebook
- 安装任何需要的库——Plotly、seaborn、scikit-learn、dbt
- 构建一次性脚本或可复现的流水线
- 生成静态报告、交互式 D3 仪表盘或原始 CSV
- 在问题半途发生变化时灵活调整
它的工作方式就像一位资深数据工程师——灵活地为每项工作选择合适的工具,而不是被锁定在某一种模式中。
我们的结论
你不需要构建专门的数据 Agent。你需要的是给通用 AI Agent 提供基础工具。
一台云端计算机。DuckDB。Python。一个图表库。标准的、成熟的、经过数十年打磨的工具。
Agent 会比任何专用系统更好地使用它们——因为它们不受产品设计师关于数据工作"应该如何进行"的假设所束缚。它们可以探索得更广、分析得更深、呈现得更美,超越任何僵化工作流所允许的范围。
基础工具一直都在。唯一缺少的是能够真正使用它们的人——或者某种东西。现在,这个障碍已经消失了。
更少的架构。更多的工具。
这无法解决的问题
有一个困难的问题是目前任何 AI Agent——无论是专用的还是通用的——都尚未攻克的:数据语义层。
Agent 可以写出完美的 SQL。它可以制作精美的图表。但它不知道你公司里的 revenue 是指总收入减去退货,而不是净收入。它不知道 active_user 是指过去 30 天内登录的人,而不是 90 天。它不知道第四季度的数据应该排除你在十月份剥离的子公司。
这是企业和组织级别的知识——隐藏在字段背后的含义、从未写入 schema 的业务规则、存在于人脑中的上下文。再强的 SQL 能力也无法弥补不了解数据真正含义的缺陷。
这是 AI 驱动的数据工作中真正困难的问题。而这也是我们下一篇文章要写的内容:如何提取人类关于数据语义的知识,并将其输入 AI Agent,使它们能够像你的团队一样理解你的数据。